How We Built ViExam: The Data Curation Pipeline
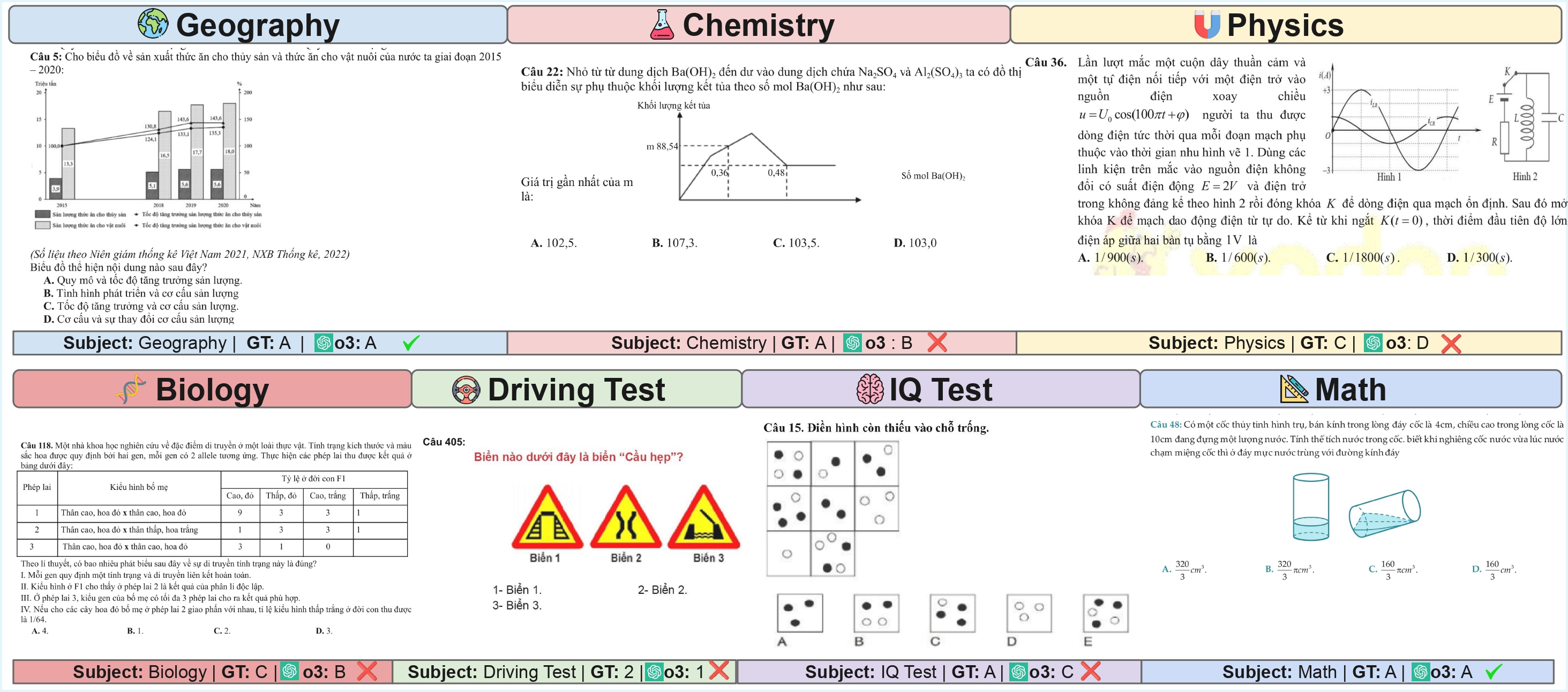
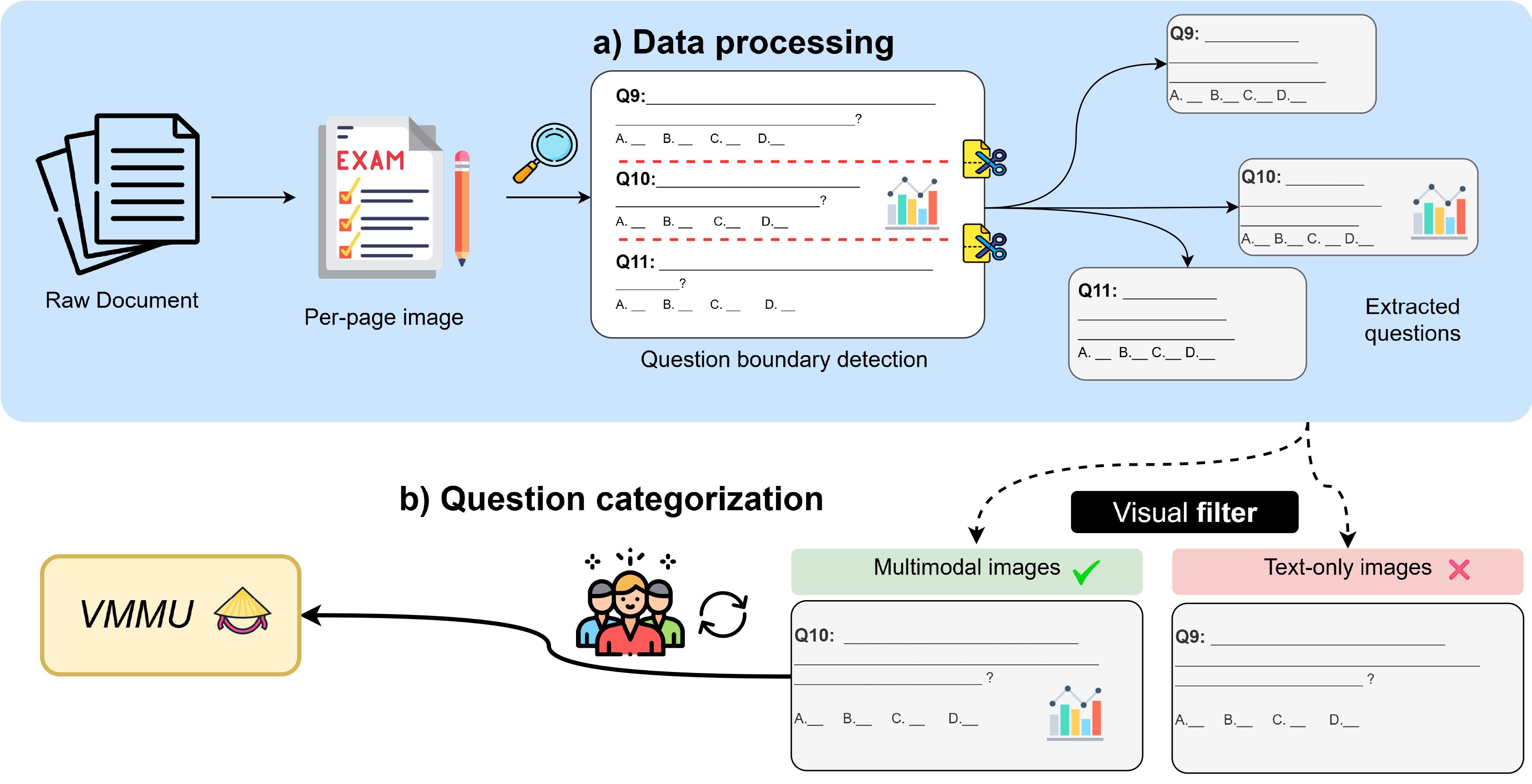
To ensure the quality and validity of our benchmark, we developed a systematic 3-stage pipeline to collect, filter, and classify exam questions. This process was crucial for building a dataset that genuinely tests multimodal reasoning, moving beyond simple text-only questions found in previous benchmarks.
Our 3-Stage Process Explained:
Stage 1: Data Sourcing & Conversion. We began by automatically crawling thousands of exam papers from popular Vietnamese educational websites. Each paper was then converted into high-resolution images, preparing them for analysis.
Stage 2: Automated Classification. Next, our custom pipeline used OCR to identify individual questions on each page. A specialized analyzer then scanned the content of each question, automatically distinguishing multimodal (image-based) questions from text-only ones.
Stage 3: Human Verification. Finally, to ensure maximum accuracy, every single question was manually reviewed by a team of native Vietnamese speakers. They used a custom-built tool to correct any classification errors and validate the final dataset.
 VMMU: A Vietnamese Multitask Multimodal Understanding and Reasoning Benchmark
VMMU: A Vietnamese Multitask Multimodal Understanding and Reasoning Benchmark